Linked List
Dalam ilmu komputer, linked list adalah kumpulan elemen data linear, yang urutannya tidak mengikuti urutan penempatan fisiknya dalam memori. Melainkan, setiap elemen menunjuk ke yang berikutnya.
Kelemahan dari linked list adalah waktu akses yang linear dan sulit untuk disalurkan. Array memiliki lokalitas cache yang lebih baik dibandingkan dengan linked list.
Dalam ilmu komputer, linked list adalah kumpulan elemen data linear, yang urutannya tidak mengikuti urutan penempatan fisiknya dalam memori. Melainkan, setiap elemen menunjuk ke yang berikutnya.
Kelemahan dari linked list adalah waktu akses yang linear dan sulit untuk disalurkan. Array memiliki lokalitas cache yang lebih baik dibandingkan dengan linked list.
Circular Singly Linked List
Circular singly linked list adalah jenis struktur data yang terdiri dari node yang dibuat menggunakan struktur referensial sendiri. Masing-masing node berisi ua bagian, yaitu data dan referensi ke list node berikutnya. Hanya referensi ke list node pertama yang diperlukan untuk mengakses seluruh linked list.

Circular singly linked list adalah jenis struktur data yang terdiri dari node yang dibuat menggunakan struktur referensial sendiri. Masing-masing node berisi ua bagian, yaitu data dan referensi ke list node berikutnya. Hanya referensi ke list node pertama yang diperlukan untuk mengakses seluruh linked list.
Circular Doubly Linked List
Circular doubly linked list adalah jenis struktur data yang lebih kompleks di mana sebuah node berisi pointer ke node sebelumnya serta node berikutnya. Circular doubly linked list tidak mengandung NULL di node manapun. Node terakhir dari list berisi address dari node pertama dari list. Node pertama dari daftar juga berisi address dari node terakhir di pointer sebelumnya.
Contoh penerapan Circular doubly linked list dalam C+/C:
// Structure of the node
struct node
{
int data;
struct node *next; // Pointer to next node
struct node *prev; // Pointer to previous node
};
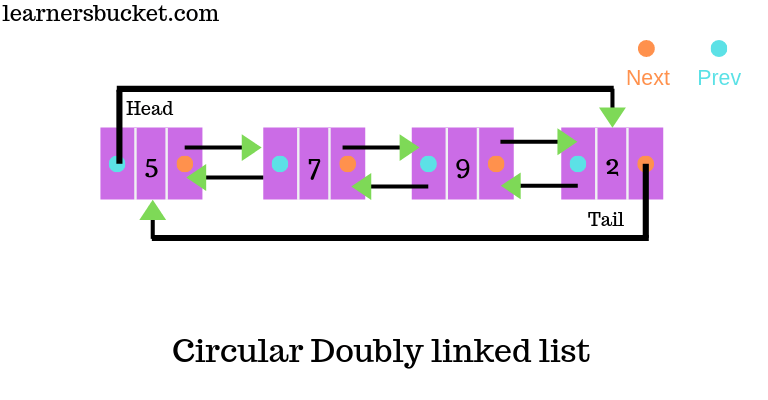
Kelebihan dan kekurangan dari circular doubly linked list:
Kelebihan:
- List dapat dilalui dari kedua arah dari kepala ke ekor atau dari ekor ke kepala.
- Melompat dari kepala ke ekor atau dari ekor ke kepala dilakukan dalam waktu konstanO(1).
- Circular Doubly Linked Lists digunakan untuk implementasi struktur data tingkat lanjut.
Kekurangan;
- Dibutuhkan sedikit memori ekstra di setiap node untuk mengakomodasi pointer sebelumnya.
- Banyak petunjuk yang terlibat saat mengimplementasikan atau melakukan operasi dalam list. Jadi, pointer harus ditangani dengan hati-hati jika tidak data dari list dapat hilang.
Pengaplikasian;
- Mengatur playlist lagu.
- Mengatur keranjang belanja website shopping
Contoh penerapan Circular doubly linked list dalam C+/C:
// Structure of the node
struct node
{
int data;
struct node *next; // Pointer to next node
struct node *prev; // Pointer to previous node
};
Kelebihan dan kekurangan dari circular doubly linked list:
Kelebihan:
- List dapat dilalui dari kedua arah dari kepala ke ekor atau dari ekor ke kepala.
- Melompat dari kepala ke ekor atau dari ekor ke kepala dilakukan dalam waktu konstanO(1).
- Circular Doubly Linked Lists digunakan untuk implementasi struktur data tingkat lanjut.
Kekurangan;
- Dibutuhkan sedikit memori ekstra di setiap node untuk mengakomodasi pointer sebelumnya.
- Banyak petunjuk yang terlibat saat mengimplementasikan atau melakukan operasi dalam list. Jadi, pointer harus ditangani dengan hati-hati jika tidak data dari list dapat hilang.
Pengaplikasian;
- Mengatur playlist lagu.
- Mengatur keranjang belanja website shopping
Doubly Linked List
Doubly linked list adalah struktur linked data yang terdiri dari satu set sequentially linked records yang disebut node. Setiap node berisi dua bidang, yang disebut link, yang merupakan referensi ke node sebelumnya dan berikutnya di urutan node. Node awal dan akhir, link sebelumnya dan berikutnya, masing-masing, menunjuk ke semacam terminator, biasanya node sentinel atau nol, untuk memfasilitasi traversal daftar.
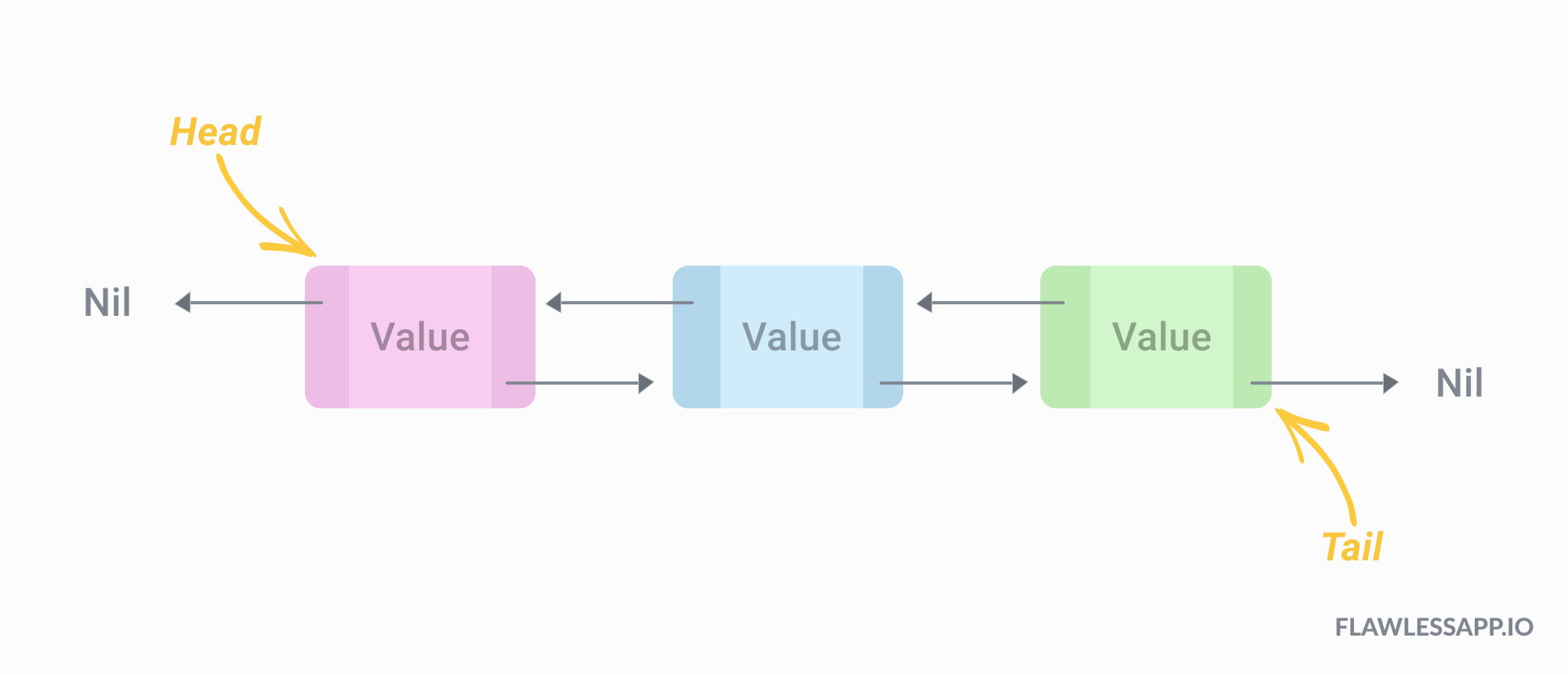 Contoh pengaplikasian node DLL dalam C+:
Contoh pengaplikasian node DLL dalam C+:
/* Node of a doubly linked list */struct Node { int data; struct Node* next; // Pointer to next node in DLL struct Node* prev; // Pointer to previous node in DLL};
Kelebihan dan kekurangan DLL dibandingkan singly linked list:
Keuntungan lebih dari singly linked list
- DLL dapat dilintasi baik maju maupun mundur.
- Operasi hapus di DLL lebih efisien jika penunjuk ke simpul yang akan dihapus diberikan.
- Kita dapat dengan cepat menyisipkan simpul baru sebelum simpul yang diberikan.
- Dalam daftar tertaut tunggal, untuk menghapus sebuah simpul, diperlukan pointer ke simpul sebelumnya. Untuk mendapatkan simpul sebelumnya, terkadang daftar ini dilintasi. Dalam DLL, kita bisa mendapatkan simpul sebelumnya menggunakan pointer sebelumnya.
Kerugian dari daftar yang singly linked list
- Setiap node DLL Membutuhkan ruang ekstra untuk pointer sebelumnya.
- Dimungkinkan untuk mengimplementasikan DLL dengan pointer tunggal.
- Semua operasi memerlukan pointer ekstra sebelum dipertahankan. Misalnya, dalam penyisipan, kita perlu memodifikasi pointer sebelumnya bersama dengan pointer berikutnya. Misalnya dalam fungsi berikut untuk penyisipan di posisi yang berbeda, kita perlu 1 atau 2 langkah tambahan untuk mengatur pointer sebelumnya.
Doubly linked list adalah struktur linked data yang terdiri dari satu set sequentially linked records yang disebut node. Setiap node berisi dua bidang, yang disebut link, yang merupakan referensi ke node sebelumnya dan berikutnya di urutan node. Node awal dan akhir, link sebelumnya dan berikutnya, masing-masing, menunjuk ke semacam terminator, biasanya node sentinel atau nol, untuk memfasilitasi traversal daftar.
Contoh pengaplikasian node DLL dalam C+:
/* Node of a doubly linked list */struct Node { int data; struct Node* next; // Pointer to next node in DLL struct Node* prev; // Pointer to previous node in DLL};
Kelebihan dan kekurangan DLL dibandingkan singly linked list:
Keuntungan lebih dari singly linked list
- DLL dapat dilintasi baik maju maupun mundur.
- Operasi hapus di DLL lebih efisien jika penunjuk ke simpul yang akan dihapus diberikan.
- Kita dapat dengan cepat menyisipkan simpul baru sebelum simpul yang diberikan.
- Dalam daftar tertaut tunggal, untuk menghapus sebuah simpul, diperlukan pointer ke simpul sebelumnya. Untuk mendapatkan simpul sebelumnya, terkadang daftar ini dilintasi. Dalam DLL, kita bisa mendapatkan simpul sebelumnya menggunakan pointer sebelumnya.
Kerugian dari daftar yang singly linked list
- Setiap node DLL Membutuhkan ruang ekstra untuk pointer sebelumnya.
- Dimungkinkan untuk mengimplementasikan DLL dengan pointer tunggal.
- Semua operasi memerlukan pointer ekstra sebelum dipertahankan. Misalnya, dalam penyisipan, kita perlu memodifikasi pointer sebelumnya bersama dengan pointer berikutnya. Misalnya dalam fungsi berikut untuk penyisipan di posisi yang berbeda, kita perlu 1 atau 2 langkah tambahan untuk mengatur pointer sebelumnya.
BASIC
Hash table adalah kumpulan pasangan nilai kunci yang tidak teratur, di mana setiap kunci unik.
HASHING
Ide pokok dalam hashing adalah untuk mendistribusikan entri (key/value pairs) di seluruh array bucket. Stelah diberi key, algoritma menghitung indeks yang menunjukkan di mana entri dapat ditemukan:
index = f(key, array_size)
Biasanya dilakukan dalam dua langkah:
Dalam metode ini, hash tidak tergantung pada ukuran array, dan kemudian dikurangi menjadi indeks (angka antara 0 danarray_size − 1) menggunakan modula operator (%).
Dalam kondisi ukuran array dapat dibagi 2, operasi sisanya dikurangi menjadi masking, yang meningkatkan kecepatan, tetapi dapat meningkatkan masalah dengan fungsi hash yang buruk.
Ide pokok dalam hashing adalah untuk mendistribusikan entri (key/value pairs) di seluruh array bucket. Stelah diberi key, algoritma menghitung indeks yang menunjukkan di mana entri dapat ditemukan:
index = f(key, array_size)
Biasanya dilakukan dalam dua langkah:
hash = hashfunc(key)
index = hash % array_size
Dalam metode ini, hash tidak tergantung pada ukuran array, dan kemudian dikurangi menjadi indeks (angka antara 0 danarray_size − 1) menggunakan modula operator (%).

Hash Function:
Secara sederhana, hash function memetakan sejumlah value ke integer kecil yang dapat digunakan sebagai indeks dalam hash table.
Fungsi hash yang baik harus memiliki syarat berikut:
- Dihitung secara efisien.
- Sebaiknya mendistribusikan kunci secara seragam (Setiap posisi meja memiliki kemungkinan yang sama untuk setiap kunci)
Choosing a hash function
Persyaratan dasar adalah bahwa function tersebut harus menyediakan distribusi nilai hash yang seragam. Distribusi yang tidak seragam akan meningkatkan jumlah tabrakan dan biaya penyelesaiannya.
Keseragaman kadang-kadang sulit untuk dipastikan dengan desain, tetapi dapat dievaluasi menggunakan uji statistik.
Fungsi hash yang baik harus memiliki syarat berikut:
- Dihitung secara efisien.
- Sebaiknya mendistribusikan kunci secara seragam (Setiap posisi meja memiliki kemungkinan yang sama untuk setiap kunci)
Persyaratan dasar adalah bahwa function tersebut harus menyediakan distribusi nilai hash yang seragam. Distribusi yang tidak seragam akan meningkatkan jumlah tabrakan dan biaya penyelesaiannya.
Keseragaman kadang-kadang sulit untuk dipastikan dengan desain, tetapi dapat dievaluasi menggunakan uji statistik.
Keseragaman kadang-kadang sulit untuk dipastikan dengan desain, tetapi dapat dievaluasi menggunakan uji statistik.
Perfect hash function
Jika semua key diketahui sebelumnya, prefect has function dapat digunakan untuk membuat perfect hash table yang tidak memiliki tabrakan. Jika minimal perfect hashing digunakan, setiap lokasi di hast table dapat digunakan juga.
Hash Table:
Struktur data yang menyimpan data secara asosiatif. Dalam hash table, data disimpan dalam format array, di mana setiap nilai data memiliki nilai indeks uniknya sendiri.
Collision Handling:
Karena fungsi hash memberi kita angka kecil untuk big key, ada kemungkinan bahwa dua kunci menghasilkan nilai yang sama. Situasi di mana key map yang baru dimasukkan ke slot yang sudah ditempati di hash table disebut collision dan harus ditangani menggunakan beberapa teknik penanganan tabrakan. Berikut adalah cara-cara untuk menangani collision:
· Chaining: Intinya adalah untuk membuat setiap sel hash table menunjuk ke linked list yang memiliki nilai fungsi hash yang sama. Chaining sederhana tetapi membutuhkan memori tambahan di luar meja.
· Open Addressing: Dalam open addressing, semua elemen disimpan dalam hash table itu sendiri. Setiap table entry berisi catatan atau NIL. Saat mencari elemen, kita satu per satu memeriksa table slot hingga elemen yang diinginkan ditemukan atau jelas bahwa elemen tersebut tidak ada dalam table.
Credits to Wikipedia, https://www.java2novice.com/, https://www.geeksforgeeks.org/, https://www.javatpoint.com/, and HackerRank on Youtube
Jika semua key diketahui sebelumnya, prefect has function dapat digunakan untuk membuat perfect hash table yang tidak memiliki tabrakan. Jika minimal perfect hashing digunakan, setiap lokasi di hast table dapat digunakan juga.
Hash Table:
Hash Table:
Struktur data yang menyimpan data secara asosiatif. Dalam hash table, data disimpan dalam format array, di mana setiap nilai data memiliki nilai indeks uniknya sendiri.
Collision Handling:
Collision Handling:
Karena fungsi hash memberi kita angka kecil untuk big key, ada kemungkinan bahwa dua kunci menghasilkan nilai yang sama. Situasi di mana key map yang baru dimasukkan ke slot yang sudah ditempati di hash table disebut collision dan harus ditangani menggunakan beberapa teknik penanganan tabrakan. Berikut adalah cara-cara untuk menangani collision:
· Chaining: Intinya adalah untuk membuat setiap sel hash table menunjuk ke linked list yang memiliki nilai fungsi hash yang sama. Chaining sederhana tetapi membutuhkan memori tambahan di luar meja.
· Open Addressing: Dalam open addressing, semua elemen disimpan dalam hash table itu sendiri. Setiap table entry berisi catatan atau NIL. Saat mencari elemen, kita satu per satu memeriksa table slot hingga elemen yang diinginkan ditemukan atau jelas bahwa elemen tersebut tidak ada dalam table.
Credits to Wikipedia, https://www.java2novice.com/, https://www.geeksforgeeks.org/, https://www.javatpoint.com/, and HackerRank on Youtube
No comments:
Post a Comment